Experiments and bets
In the ninth session we explored how to make decisions under uncertainty. Most of our ideas don't work. Accepting this reality is the first step toward building a culture of honest experimentation. A culture of experimentation doesn't necessarily mean you have to run rigorous experiments. Sometimes sliding down that slope makes things even worse.

In the ninth session of the Instituto Tramontana product management program we confronted one of the most uncomfortable truths of the craft: most of our ideas don't work. Not some. Most.
The data from leading technology companies is revealing. At Microsoft, only one third of tested ideas improve the metrics they were designed for. At Bing and Google, well-optimized domains, the success rate is 10-20%. Netflix considers 90% of what they test to be wrong. Slack reports that only 30% of monetization experiments show positive results.
Accepting this reality shouldn't paralyze us. It should free us. If failure is the norm, the goal isn't to avoid it but to learn from it quickly.
The origins of controlled experimentation
Controlled experimentation has its roots in medicine. In 1995, Guyatt popularized the hierarchy of evidence as a way to grade medical recommendations. This hierarchy places randomized controlled trials (RCTs) as the gold standard for establishing causality. Not opinions. Not correlations. Causality.
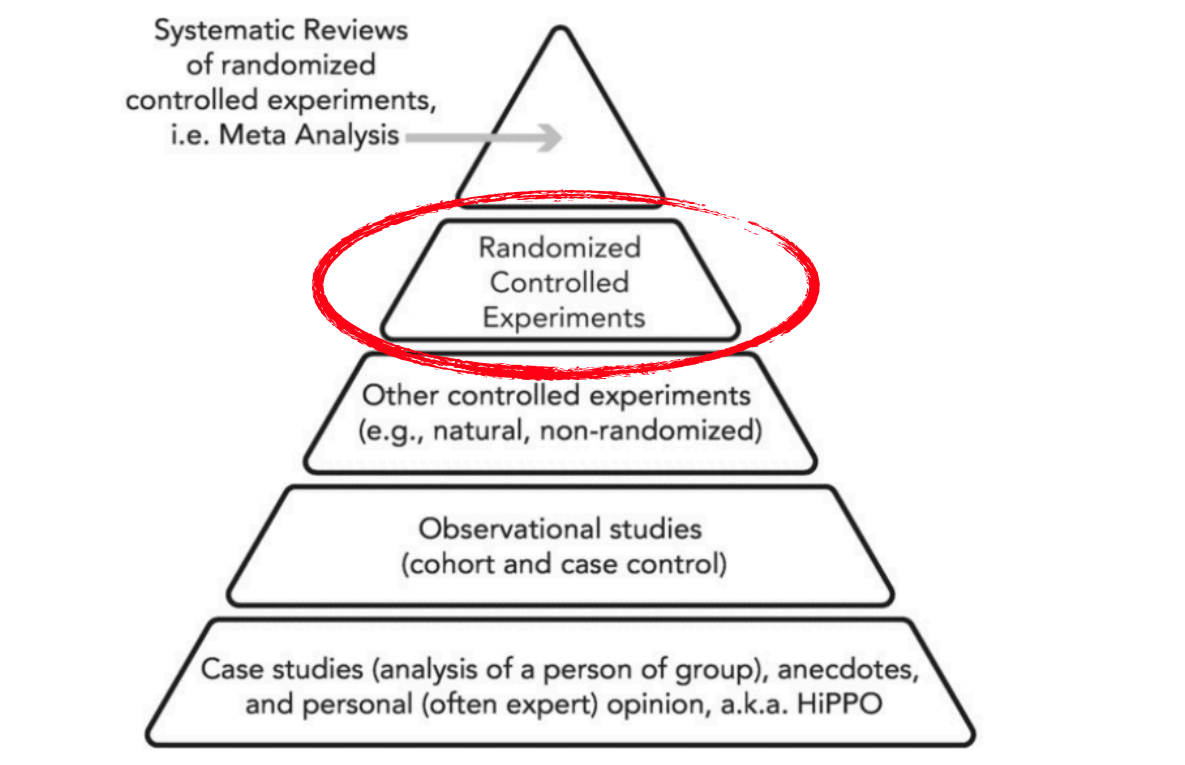
At the base are expert opinions and anecdotal cases — what in the digital product world is known as HiPPO (Highest Paid Person's Opinion). Moving up the pyramid we find observational studies, non-randomized experiments, and finally, at the top, randomized controlled trials and their meta-analyses.
This rigorous approach has been transferred to the digital world through A/B testing and other experimentation techniques. The fundamental reference book is Trustworthy Online Controlled Experiments by Ron Kohavi, Diane Tang, and Ya Xu. Kohavi, who led experimentation at Microsoft and Airbnb, rigorously documents how technology companies have adopted — and adapted — the principles of evidence-based medicine.
But experimentation in digital product has its peculiarities. Unlike clinical trials, we can iterate fast. We can fail cheaply. We can learn in short cycles. This speed is a competitive advantage if we know how to leverage it.
Decisions and outcomes: two different things
A fundamental concept from this session is separating the quality of the decision from the outcomes obtained. They are two different things, though we tend to conflate them.
Imagine a diagram with two circles. A small one represents the decision: what we control, the information we have, the analysis we perform. Another circle, much larger, represents everything else: what we don't know and luck. The final outcome emerges from the interaction of both.
The implications are important:
- A good decision can lead to a bad outcome. Bad luck.
- A bad decision can lead to a good outcome. Good luck.
- Judging the quality of a decision by its outcome is a logical error.
Annie Duke, former professional poker player and author of Thinking in Bets, puts it well: we should evaluate the decision process, not just the outcome. A poker player can make the right play and lose the hand. That doesn't mean the play was wrong.

The learning cycle
We propose a cyclical model for managing uncertainty:
Bet -> Outcome -> Learning -> Uncertainty reduction -> New bet
Each turn of the cycle makes us wiser. Not because we get more right — remember that most ideas fail — but because we reduce the space of the unknown. Each experiment, whether it works or not, gives us information we didn't have before.
This model has practical consequences:
- There are no failed experiments if we learn something. Failure is an outcome, not a mistake.
- The speed of the cycle matters. The faster we iterate, the faster we learn.
- Documentation is essential. If we don't record what we bet on, what we observed, and what we learned, we lose the value of the experiment.
Calibrating confidence
Before placing a bet, we should ask ourselves: how confident am I?
In any team you'll find different levels of confidence when facing a proposal:
- "I don't know"
- "I think so"
- "Absolutely!"
- "I don't see it"
Overconfidence leads to not experimenting when we should. If we're sure something will work, why test it? But remember the data: most ideas fail, even the ones that seem obvious.
Underconfidence leads to analysis paralysis. If we're never sure enough, we never launch anything.
The goal is to calibrate our confidence with reality. Be humble about what we don't know, but determined to learn through action.
What do we bet?
Once we understand our confidence, the next question is: what do we bet?
This means defining with clarity:
- What resources we invest. Time, money, people. Every bet has a cost.
- What metrics we'll measure. Without clear metrics there's no experiment, only opinions.
- How much time we'll give it. An experiment without a closing date is not an experiment.
- What decision we'll make based on the results. If A, we'll do X. If B, we'll do Y. Defining this beforehand avoids the bias of interpreting results to suit our preferences.
Here we connect directly with what we saw in session 7 about metrics. The behavioral metrics and financial metrics we learned to build are the ones we use to evaluate our experiments. Without good metrics, there is no good experimentation.
Sample size matters
A technical but crucial point: to obtain statistically significant results, you need an adequate sample size. The general rule is more than 1,000 users per variant to detect small but significant effects.
This has important implications:
- Not all companies can run effective A/B testing. If you don't have enough traffic, the results won't be reliable.
- Small effects require large samples. If you expect a 1% improvement, you need far more users than if you expect a 50% improvement.
- Experiment duration depends on traffic. More traffic = faster results.
For those without sufficient volume, there are alternatives: qualitative research, user testing, cohort analysis. They're not the gold standard of RCTs, but they're better than validating nothing.
The gold standard trap
Here comes a warning I consider important: randomized experimentation as the gold standard cannot be cheerfully transplanted to digital product. It's often done, and it often goes wrong.
The problem is that rigorous experimentation demands resources. Many of them. Designing an experiment well, instrumenting it correctly, obtaining significant samples, analyzing the results with statistical rigor, documenting the learnings... All of that costs time and people. And while you invest in that machinery, you may be drifting away from what really matters: knowing your customers, understanding their problems, building solutions that work.
I've seen too many times how product teams plunge into enormous complexity — experimentation platforms, metrics dashboards, validation processes — without any of it translating into better decisions. It becomes a paint-by-numbers exercise: the form is there, but the substance is not.
The reality is that most of what companies call "experiments" are not experiments in the strict sense. They are measured bets. We do something, measure what happens, and draw conclusions. That's fine. It's useful. But it's not an RCT. It doesn't establish causality with rigor. It doesn't control for confounding variables.
And that's okay. For most product decisions, a measured bet is enough. What matters is being honest about what we're doing. Not calling an observation an "experiment." Not attributing causality to what is correlation. Not investing in experimentation machinery you won't use well.
The balance of forces matters. Before building an experimentation infrastructure, ask yourself: do we have the necessary volume? Do we have the analytical capabilities? Do we have the discipline to execute real experiments? If the answer is no, perhaps it's better to invest those resources in talking to customers, observing behaviors, and making reasonable decisions with the information you have.
Biases: the silent enemy
Cognitive biases affect the entire experimentation process:
- How we design experiments. We tend to design tests that confirm what we already believe.
- How we interpret results. We look for explanations that fit our expectations.
- What we decide to do. We ignore results we don't like.
Confirmation bias is especially dangerous. Avinash Kaushik, digital analytics evangelist, put it bluntly: "80% of the time we are wrong about what the customer wants." But we rarely feel wrong. We feel certain.
Rigorous experimentation is, in part, a mechanism to protect us from ourselves. Define the rules before seeing the results. Commit to action before knowing the outcome. Document so that others can verify.
A culture of honest experimentation
The session ended with a reflection on what it really means to build a culture of experimentation. It's not just having A/B testing tools. It's accepting that:
- Most of our ideas won't work.
- That's fine. It's normal.
- The goal is to learn fast, not to be right.
- An idea discarded after a well-executed experiment is a success, not a failure.
Fareed Mosavat, Director of Product at Slack, sums it up well: "If you're on an experimentation-oriented team, get used to 70% of your work being thrown away." This requires a deep mental shift. Stop identifying with our ideas. See experiments as questions, not personal bets.
Experimentation is not a technique. It's an attitude toward uncertainty.
Session practice
Case study: Designing a real experiment. We worked on a scenario from the program repository where an organization wants to make an evidence-based decision. The exercise consisted of designing the complete experiment: hypothesis, metrics, sample size, duration, and decision rules based on possible outcomes.
Homework: Continue with the repository exercise, now working with the provided dataset. The goal was to analyze the results of a simulated experiment, apply the concepts of statistical significance, and make a well-founded decision. An exercise in going from data to consequences.